2.5. Reconocimiento de los Componentes Léxicos
|
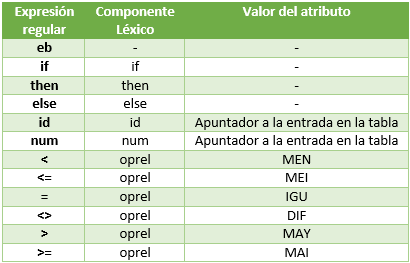
En esta sección, se estudia el reconocimiento de los componentes léxicos y se utiliza como ejemplo el lenguaje generado por la siguiente gramática. prop -> if expr then prop | if expr then prop else prop |Є expr -> término oprel término | término término -> id | núm donde los terminales if, then, else, oprel, id y núm generan conjuntos de cadenas dados por las siguientes definiciones regulares: if -> if then -> then else -> else oprel -> < | <= | = | <> | > | >= id -> letra ( letra | digito )* núm-> digito+( . dígito+)? (E( + | - )? dígito+ .. )? donde letra y dígito se han definido anteriormente. Para este fragmento de lenguaje, el analizador léxico reconocerá las palabras clave if, then, else, al igual que los lexemas representados por oprel, id y núm. Para simplificar las cosas, se supone que las palabras clave son reservadas; es decir, no se pueden usar como identificadores, núm representa los números enteros y reales sin signo de Pascal. Además, se supone que los lexemas están separados por espacio en blanco, formados por secuencias no nulas de espacios en blanco, caracteres TAB y caracteres de nueva línea. El analizador léxico eliminará los espacios en blanco. Esto lo hará comparando una cadena con la definición de la expresión regular eb siguiente. delim -> blanco | tab | lineanueva eb -> delim+ Si se encuentra una concordancia para eb, el analizador léxico no devuelve un componente léxico al analizador sintáctico, sino que se dispone a encontrar un componente léxico a continuación del espacio en blanco y lo devuelve al analizador sintáctico. El objetivo es construir un analizador léxico que aislé el lexema para el siguiente componente Léxico del buffer de entrada y que produzca como salida un par formado por el componente léxico apropiado y el valor de atributo, utilizando la tabla de traducción mostrada a continuación. Los valores de atributo para los operadores relacionales están dados por las constantes simbólicas MEN, MEI, IGU, MAY, MAI. |
 |